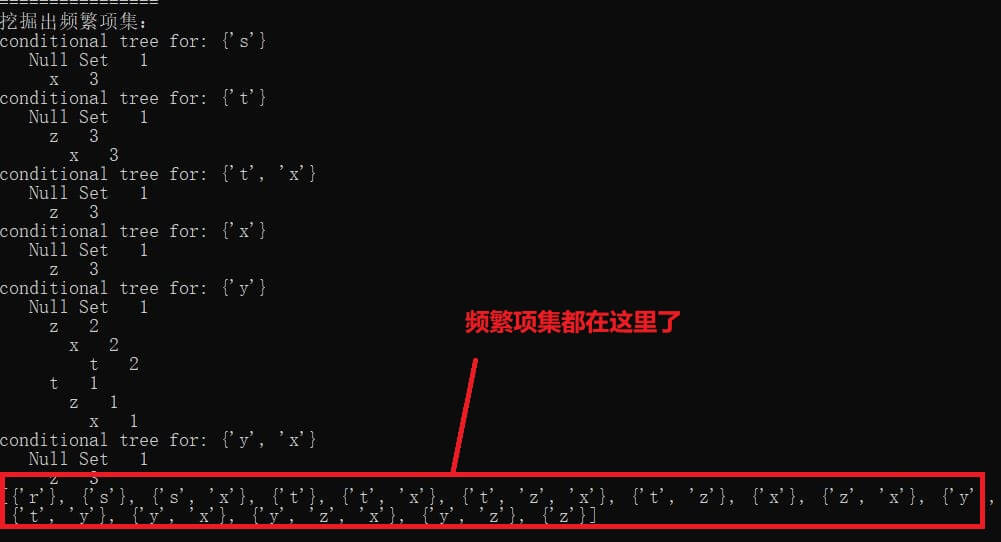
关联规则之FP-growth算法
建立FP树的类定义
复制下面7个步骤的代码到一个python文件中
1 | class treeNode: |
FP树构建函数
1 | def createFPTree(dataSet, minSup=1): |
制造一些数据
1 | def loadSimpDat(): |
构造成 element : count 的形式,如 z:5, x:3
1 | def createInitSet(dataSet): |
抽取条件模式基需要用到的函数
1 | # 递归回溯树,从本节点一直往上 |
创建条件FP树,挖掘树中的信息
1 | def mineTree(inTree,headerTable,minSup,preFix,freqItemList): |
跑起来
1 | print("构建FP树:") |
说明一下
对于这颗构建的FP树
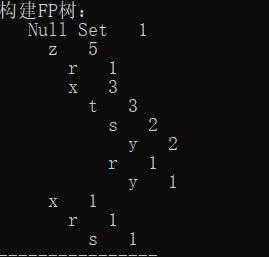
它其实是这个意思
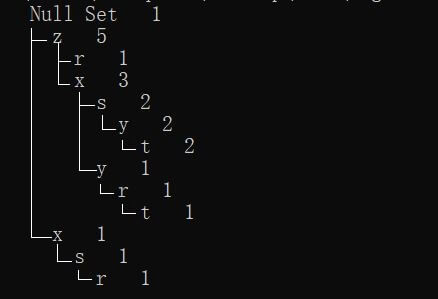
要反应的是下面这样的树结构
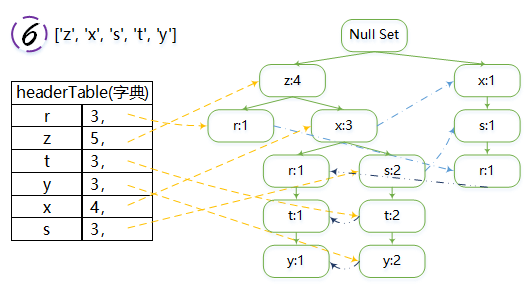
打印出来的条件模式基

其实反应的就是说的这个表
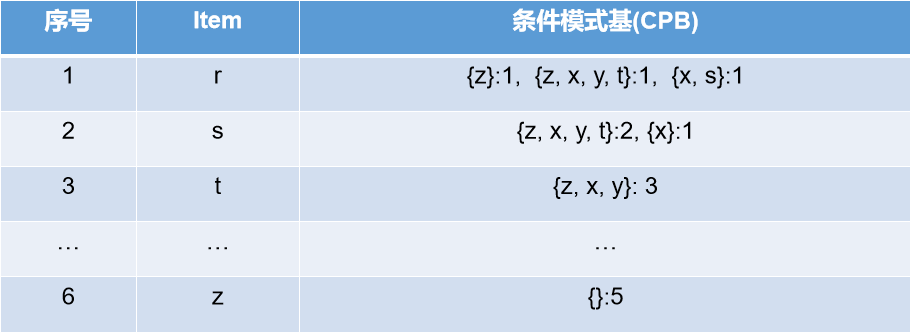
最后,这里打印出来的是频繁项集