日志的挖掘与应用
日志概念
日志是什么
所谓日志(Log)是指系统所指定对象的某些操作和其操作结果按时间有序的集合。
日志数据的核心就是简单的日志消息。
日志数据可详细累出应用程序的信息、系统性能或用户活动等。
几乎所有的计算机相关的设备、系统、网络、应用都会产生日志。
日志能做什么
- 故障排除
日志可用于还原故障现场、梳理故障条例、分析故障根源和系统调试等; - 资源管理
日志记录系统运行状态、软硬件状态、性能容量等资源使用情况信息; - 入侵检测
主机日志(不同于NIDS日志)可用于入侵检测分析; - 取证审计
各个行业都有审计安全的需求 - 数据挖掘
日志是数据挖掘的基础信息
日志处理
- 产生日志:
操作系统、数据库、中间件、应用、硬件设备等生成日志。 - 传输日志:
日志基于某种协议传输。如:SNMP、Syslog协议。 - 存储日志:
日志的存储和快速检索分析。 - 分析日志:
通过某种组合命令、日志工具或系统分析日志信息,挖掘日志“内涵”。
产生日志
绝大多数IT设备均产生日志,比如:
操作系统,如Linux,Windows等
硬件服务器,如PC server,打印机等
网络设备,如路由器,交换机等
安全设备,如防火墙,防病毒系统等
数据库,如Oracle,MySQL等
中间件,如Apache等
传输日志
日志传输是将日志消息从一个地方转移到另一地方的方式。
日志记录系统获取日志的方式分为两类:
- 拉:
应用程序从来源拉取日志消息。该方式一般基于C/S模型。通常以专有格式保存日志数据。
例如:拉取CheckPoint防火墙日志。 - 推:
设备向日志记录系统推送日志数据,必须配备一个日志收集器接收消息。
例如:Syslog、SNMP、Windows事件日志。
Syslog设施(Facility)
| 设施 | 设施码 | 描述 |
|---|---|---|
| kern | 0 | 内核信息 |
| user | 1 | 随机的用户日志消息 |
| 2 | 邮件系统日志消息 | |
| daemon | 3 | 系统守护进程日志消息 |
| auth | 4 | 安全管理日志消息 |
| syslog | 5 | 系统日志 |
| lpr | 6 | 打印信息 |
| news | 7 | 新闻组信息 |
| uucp | 8 | 由uucp生成的信息 |
| cron | 9 | 计划和任务信息 |
| authpriv | 10 | 私有的安全管理日志消息 |
| ftp | 11 | ftp守护进程日志消息 |
| NULL | 12~15 | 保留为系统使用 |
| NULL | 16~23 | 保留为本地使用 |
| 级别 | 设施码 | 描述 |
|---|---|---|
| emerg | 0 | 该系统不可用 |
| alert | 1 | 需要立即被修改的条件 |
| crit | 2 | 关键事件 |
| err | 3 | 错误 |
| warning | 4 | 警告 |
| notice | 5 | 普通单重要的事件 |
| info | 6 | 有用的信息 |
| debug | 7 | 调试信息 |
-
Syslog动作
信息发送的目的地
/<filename>发送给日志文件的绝对路径
@<host>发送给远程syslog服务器IP或域名
<user>发送给指定的用户
*发送给所有用户 -
Syslog消息组成
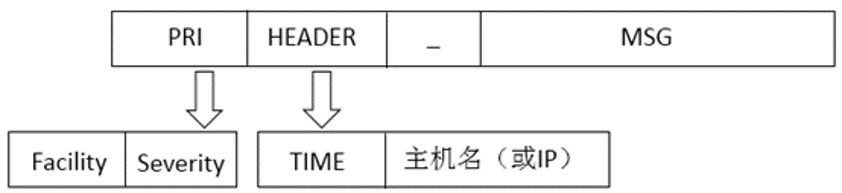
- Syslog客户端配置
编辑syslog.conf(rsyslog.conf)文件
vi /etc/syslog.conf(vi /etc/rsyslog.conf)
去掉kern前面的#符号
然后在文件中加入以下内容:
1 | *.* @192.168.186.211 |
说明: *.*和@之间为一个Tab。将设备产生的日志(类型为全部、级别为全部)发送到日志服务器192.168.186.211 和本地文件。
- 总结
推送(PUSH)技术是一种建立在客户服务器上的机制,就是由服务器主动将信息发往客户端的技术。同传统的拉(PULL)技术相比,最主要的区别在于推送(PUSH)技术是由服务器主动向客户机发送信息,而拉(PULL)技术则是由客户机主动请求信息。PUSH技术的优势在于信息的主动性和及时性。
储存日志
1 | 文本格式储存日志 |
NameNode和DataNode时HDFS的两个主要组件
NameNode负责管理存储在HDFS。上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的DataNode集合。它把该信息存储在内存中的文件分配表里。
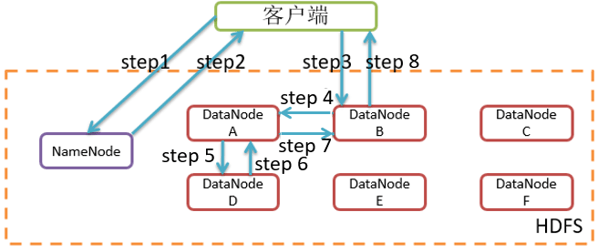
例如,客户端发送一个请求给NameNode,说它要将“abc.log”文件写入到HDFS。那么,其执行流程如下所示。具体为:
Step 1 :客户端发消息给NameNode,说要将“abc.log”文件写入。
Step 2 : NameNode发消息给客户端,叫客户端写到DataNode A、B和D,并直接联系DataNodeB。
Step 3 :客户端发消息给DataNodeB,叫它保存一份“abc.log "文件,并且发送一份副本给DataNodeA和DataNodeD。
Step 4 : DataNodeB发消息给DataNodeA,叫它保存一份“abc.log”文件,并且发送一份副本给DataNodeD。
Step 5: DataNodeA发消息给DataNodeD,叫它保存一份“abc.log”文件。
Step 6: DataNodeD发确认消息给DataNodeA。
Step 7: DataNodeA发确认消息给DataNodeB。
Step 8: DataNode B发确认消息给客户端,表示写入完成。
在分布式文件系统的设计中,挑战之一是如何确保数据的一致性。对于HDFS来说,直到所有要保存数据的DataNodes确认它们都有文件的副本时,数据才被认为写入完成。因此,数据一致性是在写的阶段完成的。一个客户端无论选择从哪个DataNode读取,都将得到相同的数据。
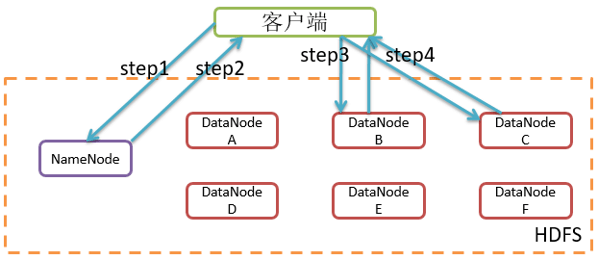
HDFS的读取步骤如下:
Step1 :客户端询问NameNode它应该从哪里读取文件。
Step2 : NameNode发送数据块的信息给客户端。数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块ID.
Step3 :客户端检查数据块信息,联系相关的DataNode,请求数据块。
Step4 : DataNode返回文件内容给客户端,然后关闭连接,完成读操作。
客户端并行从不同的DataNode中获取一个文件的数据块,然后联结这些数据块拼成完整的文件。
日志分析
日志信息应该包括:
WHO(涉及谁?)、WHAT(发生了什么?)、WHERE(发生在哪里?)、WHEN(发生在何时?)、WHY(为什么发生?)、HOW(如何发生?)
日志分析命令
grep更适合单纯的查找或匹配文本
awk 更适合格式化文本,对文本进行较复杂的格式处理
sed 更适合编辑文本
grep
-
grep常用参数
-c只输出匹配行的个数。
-i不区分大小写(只适用于单字符)。
-h查询多文件时不显示文件名。
-l查询多文件时只输出包含匹配字符的文件名。
-n显示匹配行及行号。
-s不显示不存在或无匹配文本的错误信息。
-v显示不包含匹配文本的所有行。
--color:以特定颜色高亮显示匹配关键字 -
grep pattern正则常用参数
^锚定行的开始 如:^grep匹配所有以grep开头的行。
\$锚定行的结束 如:grep\$匹配所有以grep结尾的行。
.匹配一个非换行符的字符 如:gr.p匹配gr后接一个任意字符,然后是p。
*匹配零个或多个先前字符 如:*grep匹配所有一个或多个空格后紧跟grep的行。.*一起用代表任意字符。
[]匹配一个指定范围内的字符,如[Gg]rep匹配Grep和grep。
\<从匹配正则表达式的行开始
\>从匹配正则表达式的行结束
awk
-
awk 常用变量
FS:输入字符风隔符,默认为空白字符
OFS:输出字段分隔符,默认为空白 字符
RS:输入记录分隔符(输入换行符),指定输入时的额换行符
NF:number of Field,当前行的字段的个数,字段数量
NR:行号,当前处理的文本行的行号
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数 -
awk 常用运算符
= += -= *= /= %= ^= **=赋值
||, &&逻辑或, 逻辑与
~ ~!匹配正则表达式和不匹配正则表达式
< <= > >= != ==关系运算符
+ -加,减
* / &乘,除与求余
+ - !一元加,减和逻辑非
^ ***求幂
++ --增加或减少,作为前缀或后缀
sed
-
sed 常用参数
–n特殊处理某一行
–i修改更改文件内容
–s替换取代
–P列印
–d删除 -
sed 常用命令
a\: 新增,a的后面可以接字符串,这些字符串会出现在新一行
i\: 插入,i的后面可以接字符串,这些字符串会出现在目前行的前一行
c\: 替换,c的后面可以接字符串,这些字符串可以替换n1,n2之间的行
d: 删除
p: 打印,通常与sed -n一起使用
s: 可以部分替换,s动作可以搭配正则表达式。 如:1,20s/old/new/g
head/tail
head用于查看具体文件的前面几行内容
tail用于查看具体文件的后面几行内容
如head –n 10 /etc/passwd | grep nologin