聚类
聚类概述
概述
聚类是一个将数据集划分为若干组或簇的过程,使得同一类的数据对象之间的相似度较高,而不同类的数据对象之间的相似度较低。
这里的类,也叫簇(cluster),是相似数据的集合。
聚类的过程
把相似数据归并到一类的过程,形成同类对象具有共同特征, 不同类对象之间的有显著区别,直到所有数据的归类都完成。
- 特征性描述:对象的共同特征
- 区别性描述:不同类对象之间的区别
- 概念描述:特征性描述和区别性描述
聚类的目的
通过数据间的相似性把数据归类,并根据数据的概念描述,来制定对应的策略。
例如在电子商务领域,电商可以对有相似浏览行为的客户进行归类,从而找出他们的共同特征,达到充分理解客户需求的目的,并提供相适应的客户服务。
聚类的技术
聚类技术主要包括传统的模式识别方法和数学分类学。上个世纪80年代初,聚类技术概念被提出,其要点是在划分对象时不仅考虑对象之间的距离,还要求划分出的类具有某种内涵描述,从而避免了传统技术的某些片面性。
聚类分析方法
聚类的评价标准
purity
\begin{equation}
\operatorname{purity}(\Omega, \mathbb{C})=\frac{1}{N} \sum_{k} \max {j}\left|\omega{k} \cap c_{j}\right|
\end{equation}
Ω = {ω₁,ω₂, . . . , ωk}是聚类(cluster)的集合,ωk表示第k个聚类的集合;
C = {c₁, c₂, . . . , cj}是数据对象类型(class)的集合,cj表示第j个数据对象类型集;
N表示数据对象总数。
对象类型(class) 包括x , o , □, N=17
purity=(5+4+3)/N=12/17≈0.71
purity是简单透明的方法,它的取值在0—1之间,数值越大,表示聚类效果越好。
在大量数据经聚类算法后,如果得到的聚类(cluster)数较多时,它评价的准确性较好,但如果得到的聚类数多到极端程度,它的准确性反而较差,例如,将每个数据对象都聚成一类,那么Purity值为1,显然这种场合不适合。不能单纯地为了获得高Purity去追求高聚类数而牺牲聚类的质量。
Rand Index
\begin{equation}
d\left(X i_{1}, X_{j}\right)=\sqrt[2]{\sum_{k=1}^{p}(X i k-X j k)^{2}}
\end{equation}
TP:计算每个聚类中同类对象归类到同一类的组合(一对)次数,并累计所有的结果
TN:计算每个不同类对象归类到不同类的组合次数,并累计所有的结果
FP:计算每个聚类中不同类对象归类到同一类的组合次数,并累计所有的结果
FN:计算每个同类对象归类到不同类的组合次数,并累计所有的结果
聚类方法
划分聚类算法(Partitioning Methods)
层次聚类算法(Hierarchical Methods)
基于密度的聚类算法(Density-based Methods)
基于网格的聚类算法(Grid-based Methods)
基于模型的聚类算法(Model-Based Methods)
欧氏距离
在一个p维空间中,任一点Xi表示为(Xi1, Xi2,…, Xip),
它与另一点Xj的欧氏距离d(Xi, Xj)可按如下方法计算
\begin{equation}
\mathrm{RI}=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{FP}+\mathrm{FN}+\mathrm{TN}}
\end{equation}
划分聚类算法(Partitioning Methods)
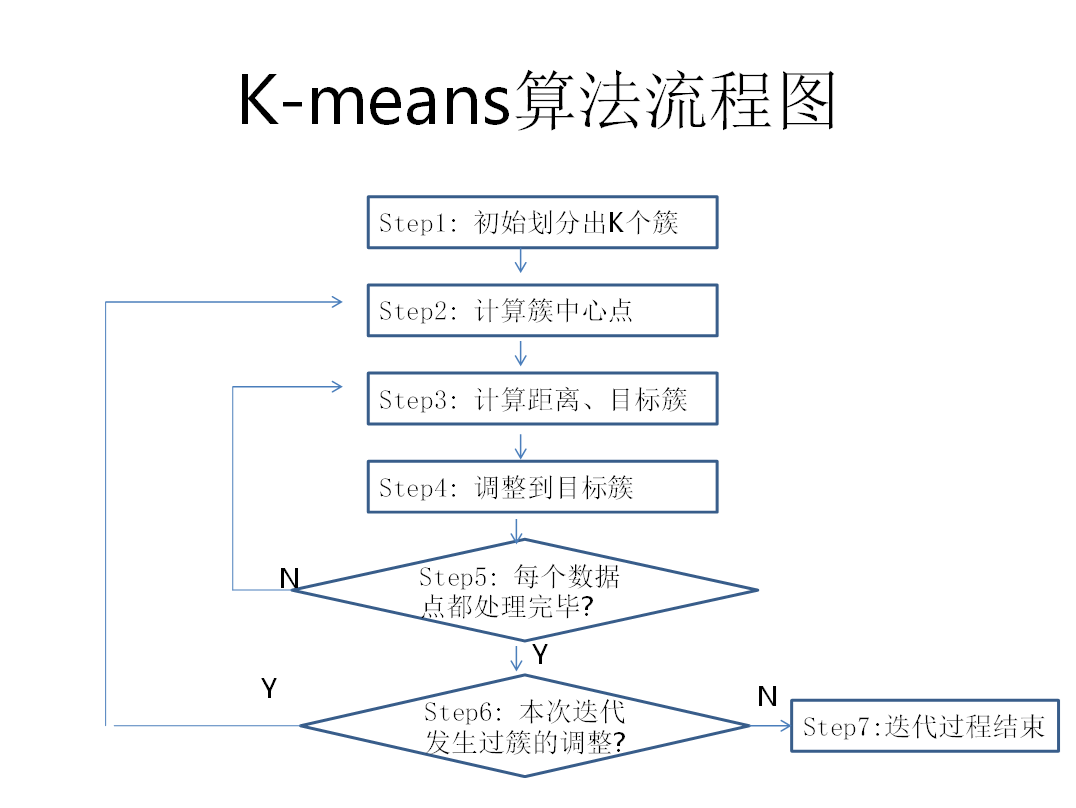
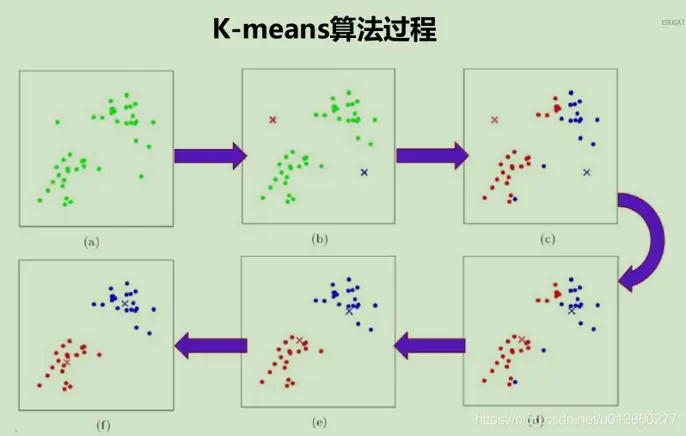
k-means
先预设划分的分类数K,将给定的数据划分成K个非空集合,即簇,然后通过调整每个数据在各簇的分布,使得每个簇的相似度得到进一步提高,而簇之间的相异度加大。不断重复这个过程,直到每个簇不再改变。
基于密度的聚类算法(Density-based Methods)
代表算法DBSCAN (Density-Based Spatial Clustering of Applications with Noise):
根据数据对象的密度来划分簇,目标是寻找被低密度区域分离的高密度区域。
核心点:如果某个点的密度达到算法设定的阈值,则称其为核心。(即r领域内点的数量不小于minPts)
e-领域的距离阈值: 设定的半径r
边界点:落在核心点邻域内的点
噪声:不是核心点也不是边界点的点
直接密度可达:若某点P再点Q的r邻域内,且Q是核心对象,则P-Q是直接密度可达。
密度可达:如果有一个点的序列Q0, Q1, ..., Qk,对任意的Qi-(Qi-1)是直接密度可达,则称Q0到Qk,这实际上就是直接密度可达的“传播”。
密度相连的点:所有密度可达的点构成密度相连的点。
算法的目标:找出密度相连的点的最大集合。
基于网格的聚类算法(Grid-based Methods)
将数据对象以网络结构划分成若干网络,计算网格内的密度,再根据密度聚类。
基于模型的聚类算法(Model-Based Methods)
为每个数据簇假定一个模型,并以此判别每个数据与该模型的吻合度来聚类。
统计学方法: EM
神经网络方法:COBWEB
EM算法思想:
目标:估计A、B两个数值。
前提条件:
在开始状态下,二者都是未知的
如果知道了A、B中的任何一个的值,就可以推导出另外一个的值。
方法:赋予A某个初始值,推导出B的估计值,然后以B的估计值作为它的当前值,推导出A的估计值。重复这个过程直到最后收敛,从而得到A、B的最佳估计值。所以EM是个逐步逼近的方法。
层次聚类算法(Hierarchical Methods)
对给定的数据集进行层次似的分解,直到某种条件满足为止。
通过计算各个对象的相似性,并把相似对象合在一起,由同一的父类代表他们,由此构成一棵树,父类为根节点, 其所代表的对象即构成树的子节点。
从树的构造顺序划分:
自底而上:聚合聚类
自顶而下:分裂聚类

聚合过程
聚合分析方法是层次聚类的常用方法,其聚合过程是自底而上的过程。
过程如下:
- 它将所有数据样本分别看做独立的簇。
- 计算簇的相似度,就是簇之间的距离。距离最小的相似度高。
- 将相似度最高的簇合成一个簇,在与剩余的其他簇重新聚合。
- 如此重复迭代以上聚合过程,直到所有数据样本合并为一个簇。
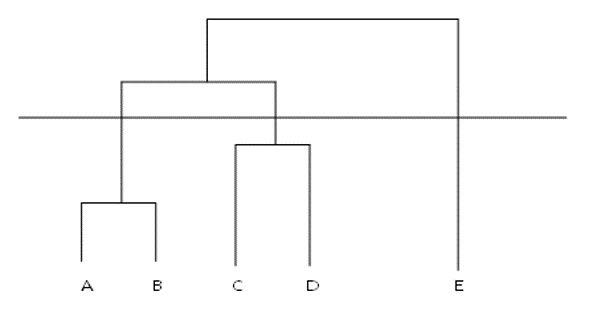
将前面的每一步的计算结果以树状图的形式展现出来就是层次聚类树。最底层是原始数据点。依照数据点间的相似度组合为聚类树的第二层。以此类推生成完整的层次聚类树树状图。
层次聚类树的作用是为我们充分展示聚类的整个过程,帮助我们从可视化的层面去了解哪些数据被归为一类。最终聚为几个类别,需要依据对不同类的特征的区隔程度阈值T来决定,在T值内的数据簇归为一类。簇的个数就是聚类的类别数。
优点
它完成了整个聚类的过程,通过聚类树,可以根据树结构来得到簇的数目。而改变簇的数目无须重新计算数据点的归类,大大提高了算法的灵活性和实用性。
缺点
计算量比较大,特别是计算平均距离。
得到的结果只是局部最优,不一定是全局最优。