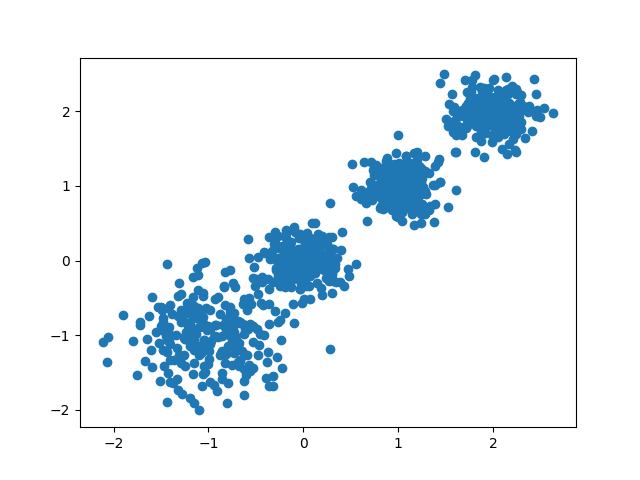
首先我们随机创建一些二维数据作为训练集,选择二维特征数据,主要是方便可视化。代码如下:
1 | import matplotlib.pyplot as plt |
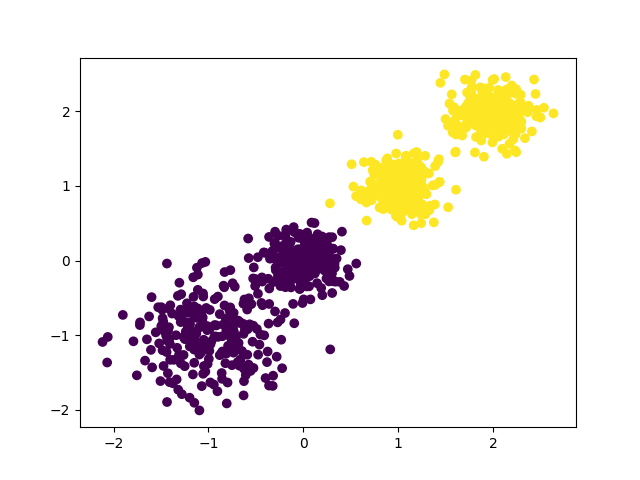
现在我们来用K-Means聚类方法来做聚类,首先选择k=2,代码如下:
1 | from sklearn.cluster import KMeans |
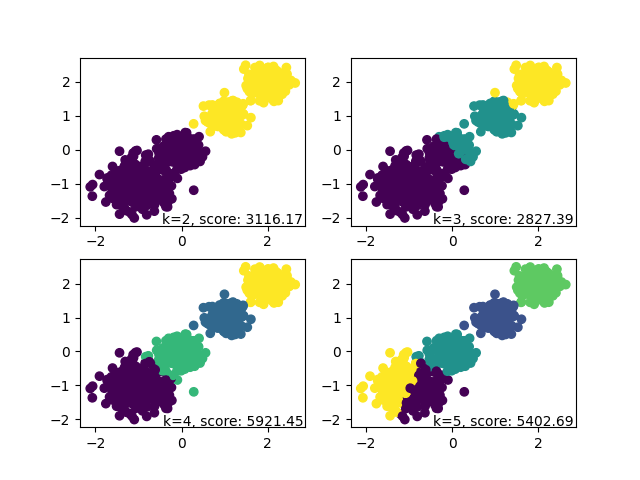
然后我们用Calinski-Harabasz Index来评估聚类的效果,这个值的得分越高越好。 (请记录下面每一次更改k值后Calinski-Harabasz Index的值),从而来判定当k选取多少的时候,聚类效果最好
1 | from sklearn import metrics |
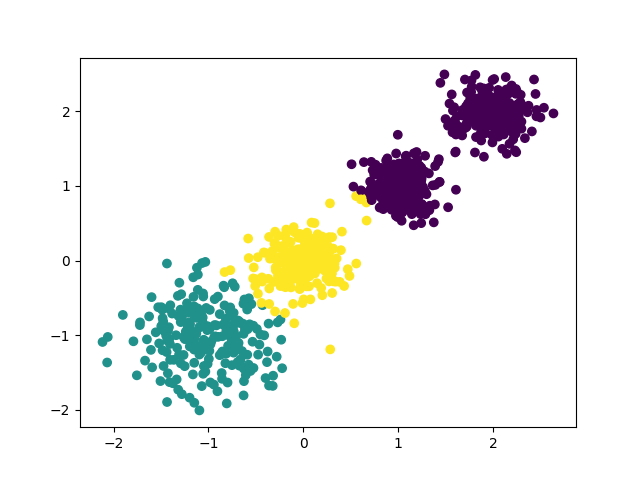
接下来让k=3,代码如下:
1 | y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X) |
运行后会画出下面的图
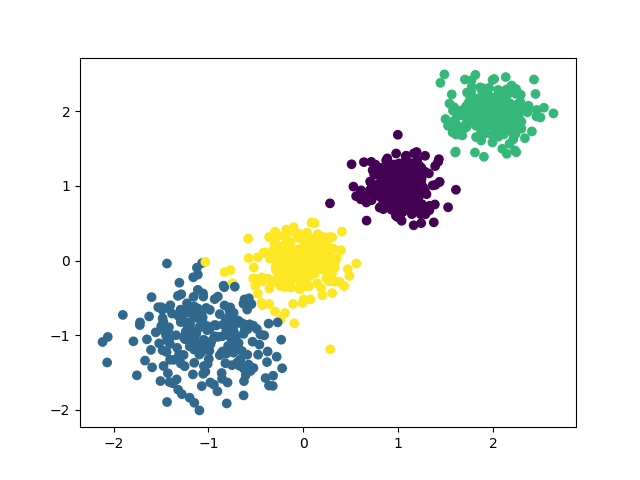
接下来让k=4,代码如下:
1 | y_pred = KMeans(n_clusters=4, random_state=9).fit_predict(X) |
运行后会画出下面的图
最后,运行下面的代码,看一下总的效果图:
1 | from sklearn.cluster import MiniBatchKMeans |
运行后会输出下面的画面