数据挖掘基础
分类概述
分类的基本概念
分类是一种重要的数据分析形式。
根据重要数据类的特征向量值及其他约束条件,建立分类函数或分类模型。
分类模型可以用于描述性建模和预测性建模。
解决分类问题的一般方法
分类法是一种根据输入数据集建立分类模型的系统方法。它包括决策树分类法、基于规则的分类法、支持向量机分类法、朴素贝叶斯分类法、神经网络等分类法。
分类算法得到的模型不仅要能拟合输入数据,同时能正确预测位置样本的类标号。
解决分类问题的一般方法如下:
第一步,建立一个模型。这需要有一个训练样本数据集作为预先的数据集或概念集,通过分析属性/特征描述等构成的样本(也可以是实体等)建立模型。
每个训练样本,都有一个预先定义的类别标记。它由一个被称为类标签的属性确定。可以表示为{ 𝑋_1, 𝑋_2, … , 𝑋_n, 𝐶 },其中𝑋_n表示属性(字段值),C表示类别。因为样本数据的类别是已知的,所以分类又被称为有监督学习。
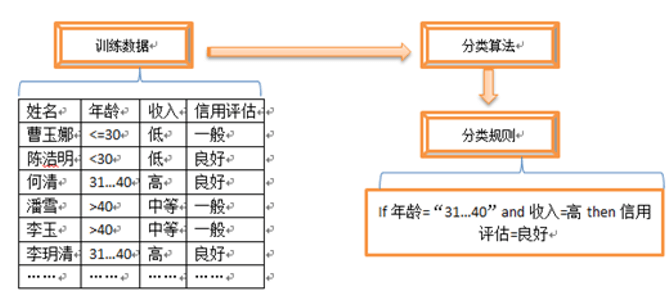
第二步,应用所建立的模型对测试数据分类进行检测。
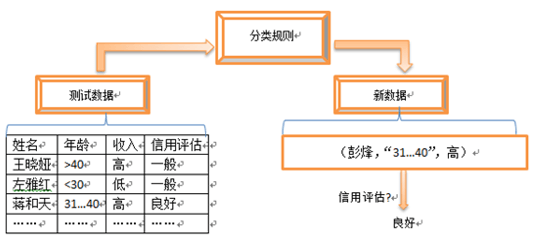
分类模型的性能可以用准确率和错误率来表示。
1 | 准确率=正确预测数/预测总数 |
1 | 错误率=错误预测数/预测总数 |
决策树
- 决策树工作原理
通过提出一系列精心构思的关于检验记录属性的问题,解决分类问题。
分类问题的决策树,树中包含三种节点:
- 根节点 没有进边,有0条或更多条出边;
- 内部节点/决策节点 有一条进边,有2条或更多条出边;
- 叶节点有一条进边,没有出边。
- 如何建立决策树
在给定的属性集中,搜索空间是指数规模的,找出最佳决策树在计算上基本很难完成。因此需要开发一些有效的算法,在合理的时间内,建立具有一定准确率的决策树。这些算法通产过度采用贪心策略,在选择划分数据的属性时,采取一些类局部最优决策建立决策树。
昆兰(Quinlan)于1983年对此进行了发展,研制了ID3算法。该算法不仅能方便地表示概念属性-值信息的结构,而且能从大量实例数据中有效地生成相应的决策树模型。
设给定正负实例的集合为S, 构成训练窗口。ID3算 法视S为一个离散信息系统,并用信息嫡表示该系 统的信息量。当决策有k个不同的输出时,S的熵 为:
\begin{equation}
\text { Entropy }(\mathrm{S}) \equiv \mathrm{H}(\mathrm{S})=-\sum_{i=1}^{\mathrm{K}} \mathrm{P}{\mathrm{i}} \log \mathrm{P}{\mathrm{i}}
\end{equation}
其中Pi表示第i类输出所占训练窗口中总的输出数量的比例。
为了检测每个属性的重要性,可以通过属性的信息增益 Gain来评估起重要性。对于属性A,假设其值域为 则训练实例S中属性A的信息增益Gain 可以定义为:
\begin{equation}
\begin{aligned}
\operatorname{Gain}(\mathrm{S}, \mathrm{A}) &=\text { Entropy }(\mathrm{S})-\sum_{i=1}^{11} \frac{\mathrm{S}{\mathrm{i}} \mid}{|\mathrm{S}|} \text { Entropy }\left(\mathrm{S}{\mathrm{i}}\right) \
&=\text { Entropy }(\mathrm{S})-\text { Entropy }(\mathrm{S} \mid \mathrm{A}) \
&=\mathrm{H}(\mathrm{S})-\mathrm{H}(\mathrm{S} \mid \mathrm{A})
\end{aligned}
\end{equation}
\begin{equation}
\text { 式中, } \mathrm{S}{\mathrm{i}} \text { 表示S中属性A的值为 } v{\mathrm{i}} \text { 的子集 } ; \mid \mathrm{S}{\mathrm{i}} \text { 表示集合的势。 }
\end{equation}
\begin{equation}
\text { Entropy }(\mathrm{S}) \equiv \mathrm{H}(\mathrm{S})=-\sum{i=1}^{\mathrm{k}} \mathrm{P}{1} \log \mathrm{P}{\mathrm{i}}
\end{equation}
\begin{equation}
\operatorname{Gain}(\mathrm{S}, \mathrm{A})=\text { Entropy }(\mathrm{S})-\sum_{\mathrm{i}=1}^{\mathrm{n}} \frac{\left|\mathrm{S}{\mathrm{i}}\right|}{|\mathrm{S}|} \text { Entropy }\left(\mathrm{S}{\mathrm{i}}\right)
\end{equation}
- 决策树归纳算法
算法2.1给出了称作Treegrowth的决策树归纳算法的框架。该算法的输入是训练记录集A和属性集B。算法递归地选择最优的属性来划分数据(步骤8),并扩展树的叶节点(步骤12和步骤13),直到满足结束条件(步骤2)。
在建立决策树的过程中,容易出现决策树太大,就是过拟合现象。这就需要对决策树进行剪枝从而减小决策树的规模。通过剪枝,有助于提高决策树的泛化能力。
1 | TreeGrowth(A,B) |
-
决策树归纳的学习算法必须解决两个问题
训练记录分裂。 决策树增长中每部都要选择一个属性测试条件,将记录划分成较小的子集。算法则是为不同类型的属性指定测试条件提供方法,并且提供评估每种测试条件的客观度量。
停止分裂过程。任何决策树又要有结束条件,从而终止决策树的无线生长。一个可能的鞠策是分裂到所有的记录都属于同一个类,或者所有的记录都具有相同的属性值。也可以使用其他的算法合理终止决策树的生长过程。 -
决策树归纳的特点
- 决策树归纳是不用假设类和其它属性服从某一分布概率,是一种构建分类模型的非参数方法。
- 找到最佳的决策树即决策树获得的不是全局最优,是每个结点的局部最优决策。
- 决策树建立后,未知样本分类很快。而已开发构建的决策树技术计算成本不高,就算训练集很大,也能快速建立模型。
- 决策树相对其它分类算法更简便,特别是小型的决策树的准确率较高。冗余属性不会对决策树的准确率造成不利的影响。
- 决策树算法对于噪声干扰有较强的抗干扰性。
- 冗余属性不会对局册数的准确率造成不利的影响。
- 决策树算法通常采用自顶向下的递归划分方法,因此沿着决策树乡下,记录就会越来越少。解决该问题通常是采用样本数小于某个特定阈值时停止分裂。
模型的过分拟合
模型过分拟合的形成
分类模型的误差可分为两类:训练误差和泛化误差。
训练误差是训练数据被错误分类的比例。
泛化误差是模型在未知数据集的期望误差。
所谓模型过分拟合是指训练数据拟合度过高的模型。
它的泛化误差可能比具有较高训练误差的模型高。具备训练数据很好拟合的同时,能对位置样本数据准确分类的模型就是一个好模型。
处理决策树归纳中的过分拟合
在这介绍两种决策树归纳上避免过分拟合的策略:
-
先剪枝(提前终止):需要采用更具限制性的结束条件。
限制树的高度,可以利用交叉验证选择
限制树的节点个数,比如某个节点小于100个样本,停止对该节点切分 -
后剪枝(过程修剪):先生成树,然后再自下向上地剪掉。
用新的叶节点替换子树,该叶节点的类标号由子树下记录中的多数类确定。
用子树中最常用的分支代替子树。当模型不能改进是,终止剪枝步骤。
与先剪枝相比,后剪枝能获得更好的结果,后剪枝是根据完全增长的决策树做出的剪枝决策。先剪枝可能过早终止决策树生长,运用后剪枝时会浪费之前通过计算生长出来的决策树。
贝叶斯决策与分类器
规则分类器
基于规则的分类器是使用一组“if…then…”规则来对记录进行分类的技术。
每个分类规则可以表示为:
1 | 𝑟_𝑖: (条件 _𝑖)→ y_𝑖 |
基于规则的分类器产生的规则集有两个重要性质:
- 互斥性 如果规则集中不存在两条规则被同一条记录触发,则称规则集中的规则是互斥的。
- 穷举性 如果属性值任一种组合,规则集中都存在一条规则加以覆盖,则称规则集具有穷举覆盖。它确保每一条记录都至少被规则集里的一条规则覆盖。
分类中贝叶斯定理的应用
-
贝叶斯定理
假设X,Y是一对随机变量,联合概率P(X=x,Y=y)是指X取值x且Y取值y的概率,条件概率是指一随机变量在另一随机变量取值已知的情况下取某一特定值得概率。
\begin{equation}
\begin{array}{l}
P(B \mid A)=\frac{P(B \cap A)}{P(A)} \
P(B \cap A)=P(B \mid A) P(A)
\end{array}
\end{equation} -
贝叶斯定理在分类中的应用
先从统计学的角度对分类问题加以形式化。设X表示属性集,Y表示类变量。如果类变量和属性之间的关系不确定,可以把X和Y看作随机变量,用P(Y|X)以概率的方式捕捉二者之间的关系,这个条件概率又称为Y的后验概率,对应P(Y)称为Y的先验概率。
在训练阶段,要根据从训练数据中收集的信息,对X和Y的每一种组合学习后验概率P(Y|X)。知道这些概率后,通过找出使后验概率P(Y|X)最大的类Y可以对测试记录X进行分类。
准确估计类标号和属性值的每一种可能组合的后验概率非常困难,因为即便属性数目不是很大,仍然需要很大的训练集。此时,贝叶斯定理可以用先验概率 P(y)、类条件概率 P(X | y)和证据P(X)来表示后验概率:
\begin{equation}
P(y \mid X)=\frac{P(X \mid y) \cdot P(y)}{P(X)}
\end{equation}
P(X)一般是常数,可以忽略。先验概率P(Y)可以通过计算训练集中属于每个类的训练记录所占的比例很容地估计。对类条件概率P(X | y)的估计,可以用朴素贝叶斯分类器和贝叶斯信念网络两种别噎死分类方法实现。
朴素贝叶斯
- 条件独立性
在研究朴素贝叶斯分类法如何工作之前,先介绍条件独立概念。设X,Y和Z表示三个随机变量的集合。给定Z,X条件独立于Y,如果下面的条件成立:
\begin{equation}
\mathrm{P}(X \mid \mathrm{Y}, \mathrm{Z})=\mathrm{P}(X \mid \mathrm{Z})
\end{equation}
- 朴素贝叶斯分类器如何工作
分类测试记录时,朴素贝叶斯分类器对每个类Y计算后验概率:
\begin{equation}
P(Y \mid X)=\frac{P(Y) \Pi_{i=1}^{d} P\left(x_{i} \mid Y\right)}{P(X)}
\end{equation}
朴素贝叶斯分类法使用两种方法估计连续属性的类条件概率。
- 可以把每一个连续的属性离散化,然后用相应的离散区间替换连续属性值。
- 可以假设连续变量服从某种概率记录,然后使用训练数据估计分布的参数。
- 朴素贝叶斯分类器特征
- 在面对孤立的噪声点,朴素贝叶斯分类器性能影响不大;
- 面对无关属性,朴素贝叶斯分类器性能同样影响不大;
- 相关属性可能降低朴素贝叶斯分类器的性能。
\begin{equation}
\begin{array}{c}
P\left(Y \mid X_{1}, \ldots, X_{n}\right)=\frac{P\left(X_{1}, \ldots, X_{n} \mid Y\right) P(Y)}{P\left(X_{1}, \ldots, X_{n}\right)} \
P\left(X_{1}, \ldots, X_{n} \mid Y\right)=\prod_{i=1}^{n} P\left(X_{i} \mid Y\right)
\end{array}
\end{equation}
支持向量机
概述
支持向量机(Support Vector Machine),以下简称SVM,已是一种备受关注的分类技术,在解决小样本,非线性、高维模式识别中具备特有的优势。已经在实际应用(如手写数字的识别、文本分类等)中展示了不俗的实践效果。
线性可分
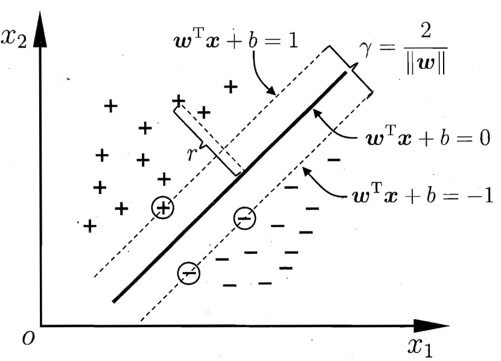
由拉格朗日可得到原问题的Karush-Kuhn-Tucker(KKT)条件:
\begin{equation}
\begin{array}{l}
\frac{\partial L}{\partial w}=0 \
\frac{\partial L}{\partial b}=0 \
y_{i}\left[\left(x_{i} \cdot w\right)-b\right]-1 \geq 0, i=1,2, \cdots, l \
a_{i} \geq 0, i=1,2, \cdots, l \
a_{i}\left{y_{i}\left[\left(x_{i} \cdot w\right)-b\right]-1\right}=0, i=1,2, \cdots, l
\end{array}
\end{equation}
根据优化理论, (w, b) 是原问题的解当且仅当(w, b, a) 满足KKT条件。
在对偶问题或KKT条件中,每个训练数据 x 都对应一个拉格朗日乘子 a_{i}>0, 其中与 a_{t}>0 对应的数据成为支持向量。
线性不可分
\begin{equation}
\left{\begin{array}{l}
y_{i}\left(\omega^{\top} x_{i}+b\right) \geqslant 1, \quad \operatorname{los} s=0 \
y_{i}\left(w^{\top} x_{i}+b\right)<1, \quad \cos s=1-y_{i}\left(w^{\top} x_{i}+b\right)
\end{array}\right.
\end{equation}
\begin{equation}
\min {w, b} \frac{1}{2} w^{\top} w+c \sum{i=1}^{N} \max \left{0,1-y_{i}\left(\omega^{\top} x_{i}+b\right)\right}
\end{equation}
\begin{equation}
k_{i}=1-y_{i}\left(w^{\top} x_{i}+b\right)
\end{equation}
\begin{equation}
\left{\begin{array}{l}
\min {x \rightarrow b} \frac{1}{2} w^{\prime} w+\operatorname{los} s \
s t \quad y{i}\left(\omega^{\prime} x_{1}+b\right) \geqslant 1
\end{array}\right.
\end{equation}
\begin{equation}
\begin{array}{l}
\min {w, b} \frac{1}{2} w^{\prime} w+c \sum{i=1}^{y} \varepsilon_{i} \
s_{t} \cdot y_{i}\left(w^{\top} x_{i}+b\right) \geqslant 1-\xi_{i}
\end{array}
\end{equation}
核函数
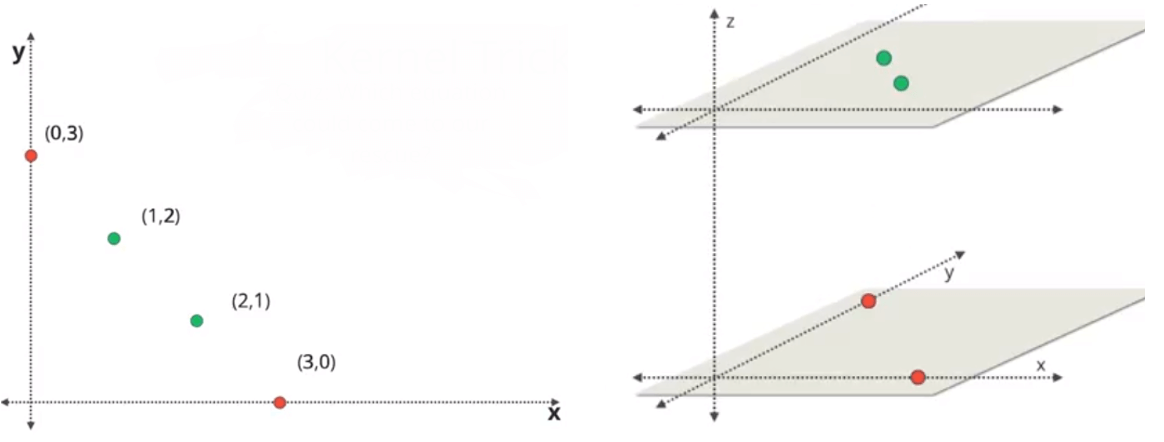
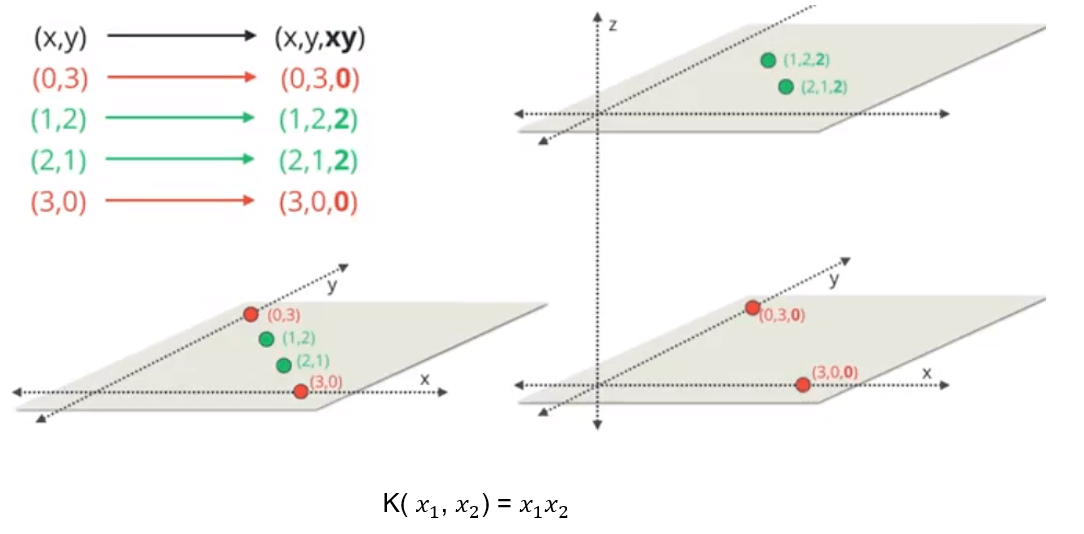
多项式核函数
\begin{equation}
K\left(x, x_{i}\right)=\left[\left(x, x_{i}\right)+1\right]^{q}
\end{equation}
径向基函数
\begin{equation}
K_{r}\left(\left|x-x_{i}\right|\right)=\exp \left{-\frac{\left(\left|x-x_{i}\right|\right)^{2}}{\sigma^{2}}\right}
\end{equation}
多层感知机
\begin{equation}
K\left(x_{i}, x_{j}\right)=\tanh \left(v\left(x_{i}^{T} * x_{j}\right)-c\right)
\end{equation}
分类
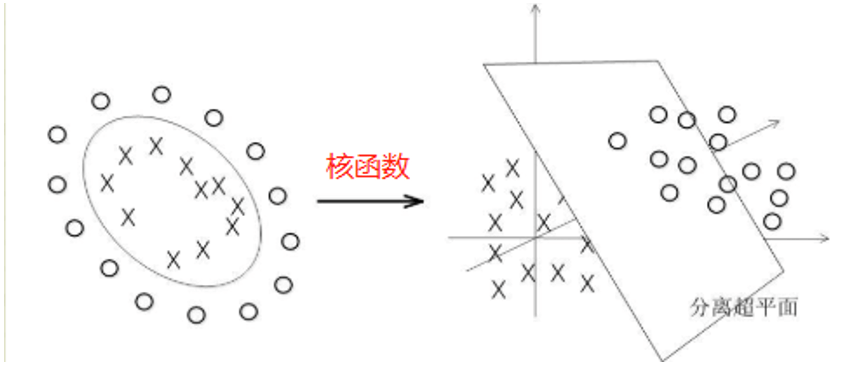
支持向量机的一般特性
- SVM学习问题可表示为凸优化问题,利用已知的有效算法发现目标函数的全局最小值。
- SVM通过最大化决策边界的边缘来控制模型。
- 通过对数据中每个分类属性值引入一个哑变量,SVM可应用于分类数据。