在实际开发中,有时候需要将HDFS或Hive上的数据导出到传统关系型数据库中(如MySQL、Oracle等),或者将传统关系型数据库中的数据导入到HDFS或Hive上,如果通过人工手动进行数据迁移的话,就会显得非常麻烦。为此,可使用Apache提供的Sqoop工具进行数据迁移。
Sqoop概述
Sqoop简介
Sqoop是Apache的一款开源工具,Sqoop主要用于在Hadoop和关系数据库或大型机之间传输数据,可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中的数据转换导出(export)到关系数据库管理系统。
Sqoop原理
Sqoop是传统关系型数据库服务器与Hadoop间进行数据同步的工具,其底层利用MapReduce并行计算模型以批处理方式加快数据传输速度,并且具有较好的容错性功能,工作流程如下所示。
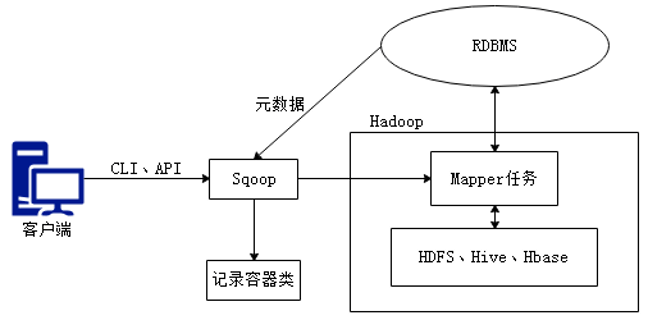
Sqoop是关系型数据库与Hadoop之间的数据桥梁,这个桥梁的重要组件是Sqoop连接器,它用于实现与各种关系型数据库的连接,从而实现数据的导入和导出操作。
导入原理
在导入数据之前,Sqoop使用JDBC检查导入的数据表,检索出表中的所有列以及列的SQL数据类型,并将这些SQL类型映射为Java数据类型,在转换后的MapReduce应用中使用这些对应的Java类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
导出原理
在导出数据前,Sqoop会根据目标表的定义生成一个Java类,这个生成的类能够从文本中解析出记录数据,并能够向表中插入类型合适的值,然后启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。